Temporal Difference (TD) learning is the most novel and central idea of reinforcement learning. It combines the advantages from Dynamic Programming and Monte Carlo methods.
Temporal Difference (TD) Prediction

The TD method (in particular one-step TD(0)) updates the state-value function as following:
![]()
At each time step, the state-value of the previous state is updated using the value observed at the current time step.
As a reminder below are the MC update and DP update:
- MC method:
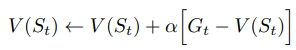
- Difference from the TD update:
- In MC, the state-value is updated by the return Gt which is only observed at the end of the episodes
- In TD, the state-value is updated immediate in the next time step (online). This result in much faster converge in TD estimation.
- Similarity to the TD update:
- Both methods does not require the model of the environment to update the state-value function
- DP method:
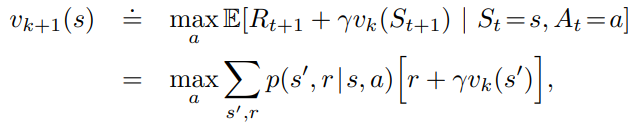
- Difference from the TD update:
- In DP, the greedy approach requires a sweep of the action space
- In TD, only the visited action is used during a trajectory
- Similarity to the TD update:
- Both methods are bootstrap methods because they use the same state-value function to update the state-value function
Optimality of Temporal Difference (TD) learning
Batch update of TD:
- The increment at every time step t when visiting a non-terminal state
- The state-value function v is only updated once by the sum of all the increments
- After each new episode, all episodes seen so far is treated as a batch (repeated presented to the algorithm)
Example
Let’s say you want to predict the state-value function manually from the below 8 episode of observations (with State = A/B, followed by reward)

- It’s easy to observe that V(B)=3/4 because there are 6 cases of return of 1 and 2 cases of return of 0
- For A, TD and MC treat it differently
- MC
- MC sees only one example with state A, which has 0 return, so it estimates V(A)=0
- MC produces the minimal mean-squared error on the training set
- TD(0) batch
- TD(0) batch uses the V(B)=3/4 to estimate V(A)=3/4
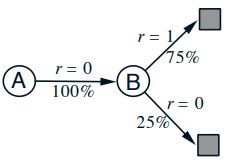
- The answer given by TD will match our expectation from the transition diagram above.
- TD produce the maximum-likelihood model of the Markov process. If we believe the process is Markov, TD is more suitable.
- This is called “certainty-equivalence estimate” because it’s equivalent to assuming we know the estimate of the underlying process with certainty rather than approximated (I need to understand it better)
- Nonbatch TD(0) can even move faster to convergence than MC because it still moving toward a better estimate than MC.
- MC
Reference: most of the material of this post comes from the book Reinforcement Learning
One thought on “Temporal Difference Learning”