In 2022, the NLP (natural language processing) benchmarks have been dominated by transformer models, and the attention mechanism is one of the key ingredients to the success of these transformer language models. Without understanding the attention mechanism, it’s difficult to appreciate many of the SOTA (state-of-the-art) models today in NLP such as BERT/GPT-3/T5 in the year 2022.
So what is attention? In this article, we will look into the definition and some examples of the attention mechanism.
Background (RNN refresher)
Let’s start with basic RNN (recurrent neural network) using traditional RNN structures such as vanilla RNN/GRU/LSTM. They are powerful because they can ingest input features as variable length, which can represent sentences of different length. They are typical expressed below in 2 forms: (left) compact form and (right) unrolled form.

It’s possible to build a sequence to sequence (seq2seq) model for a machine translation task.
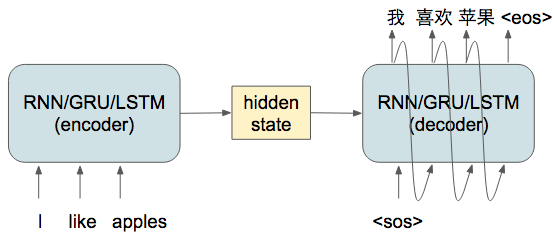
However, one of the problem of this kinds of seq2seq model is that all the information is capture in the hidden state which has a fixed dimension, which is known as an information bottleneck. The consequence of this bottleneck is the performance degradation as the length of the input sequence increases.
Key result
An attention mechanism is introduced by D. Bahdanau, K. Cho, and Y. Bengio. 2014 and it showed much improvement in BLEU score for long sentence translation performance.
- RNNenc-30/50 refers to the plain seq2seq model trained with sentences of length up to 30/50
- RNNsearch-30/50 refers to the seq2seq model with attention mechanism trained with sentences of length up to 30/50
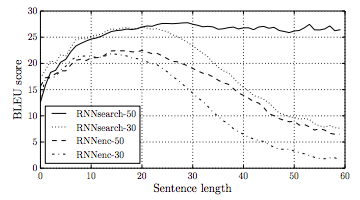
We notice that RNNenc-50 (vanilla seq2seq model trained with length 50) cannot perform well during prediction for sentences of length higher than 30. In contrast, RNNsearch-50 can continue to learn at longer sentences length.
Attention Mechanism
The goal of the attention mechanism is to break the information bottleneck between the encoder and decoder in traditional seq2seq model. But is that the own way to break the information bottleneck? Not necessarily. It’s possible to pass all hidden states information from the encoder to the decoder as a context vector.
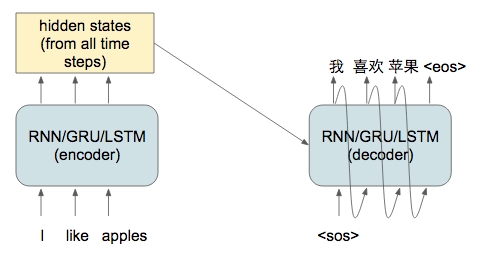
While this allows all hidden states to be observed by the decoder, but it significance increases the dimension of the decoder context vector, resulting in very high memory requirement on the decoder that depends on the length of the encoded sentence.
The attention mechanism is a way to retrieve all the hidden state while maintaining a low requirement on the context vector dimension by choosing which encoder hidden states (ie. annotations) to attend to. In particular, the paper suggests using a weighted sum of the encoder states to be the context vector (ie expected annotation)
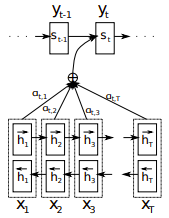
You might wonder how are these alpha weights calculated. They are calculated by a softmax over the alignment model:
![]()
where
- alpha(i, j) represents how well is the input at position j is matched with the output at position i
- e(i, j) is the called the energy which is the pre-softmax values of alpha
![]()
The energy in this paper is calculated using a neural network called the alignment model (a feed forward network) denoted by a
- The alignment network is also trained
- The energy at output position i from input position j depends on the hidden state of the decoder from the previous step i-1 and the hidden state of the input sequence at position j.
- This makes sense because such energy(i, j) needs to depends on the information accumulated so far (decoder hidden state) and the hidden state from the input at position j, and we just let the alignment network to learn the relationship.
Attention is all you need
This paper Attention Is All You Need introduced another form of attention mechanism using query, key, and value. Known as the “Scaled Dot-Product Attention”, it is another form of attention that is very efficient and powerful compared to the earlier one using a feed forward network.
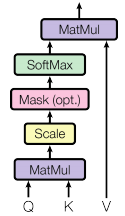
which can be expressed succinctly as
![]()
What a specifically are the Q, K, V? They are known as query-key-value. Compared to the earlier version of attention, which is additive (weighted sum), this new form of attention is multiplicative. In the simplest sense, Q and K needs to be in the same vector space as we need to dot-product them to get a value similar to the energy in the additive attention. V represents that we want to attend to at the end. There are a few different ways to mix and match these Q, K, V of this attention model in both the encoder and decoder.
The encoder-decoder attention layer
- Q (query) – comes the output of the decoder.
- K (key) – comes from the output of the previous layers of the encoder.
- V (value) – comes from the output of the previous layers of the encoder.
- Each position of the decoder can attend to all positions of the output from the encoder (final layer after a feed forward network)
The encoder self-attention layer
- Q, K, V all comes from the output of the previous layer of the encoder
- Each position of the encoder can attend to all positions of the output from the previous layer of the encoder
- For the first (lowest) layer, the query comes from the input sequence embedding directly.
The decoder self-attention layer
- Each position of the decoder can attend to all positions of the output of the previous layer of the decoder up to and including the current position.
- For the first (lowest) layer, the query comes from the output sequence embedding directly.
- Enforce auto-regressive property by masking out the future time steps.
Multi-head attention
Above is actually a simplification to help the understanding of Q, K, V. In the paper, we actually project Q, K, V into a different subspace by transformation matrices.
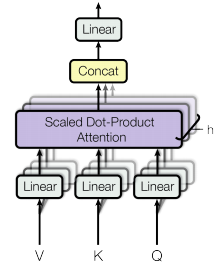
This is known as multi-head attention by keep multiple copies and of the attention functions and this can allow the projection matrices to learn different representation of Q, K, V.

The multi-head mechanism will increase the output dimension by the number of heads, so we also apply an output matrix to average or project the result back to a lower dimension. This output matrix is also a learned parameter. This helps to keep the computation cost under control when there are multiple attention layers stacked together.
Parallelism
Another benefit is that all this form of dot-product attention is parallelism. The early form (additive) attention requires the previous time step to calculate each of the following attention level, but this dot-product form of attention can be run in parallel because it can run the calculate from the previous layer.
Conclusion
You should have an intuitive understanding of the attention mechanism by now. There are a few more details about attention such as the final FFN (feed forward network), the position encoding, the skip connections, and many other improvements. However, I would like to stop the article to just focus on the attention mechanism. We see how it has evolved from solving a problem of long sequences in the seq2seq model to a more efficient and expressive form. It has shown good performance from experiment but there might be even more efficient form of attention to be discovered!
Try it yourself
Take a look at Transformer NLP Tutorial in 2022: Finetune BERT on Amazon Review
One thought on “NLP: what is attention mechanism?”