Problem
A model is too large to fit on one machine.
- Space – Too many weights to fit in memory
- Time – Too many training samples to iterate
Solution
Distributed training has two broad type
- Model parallelism (harder)
- When model parameters do not fit on one device
- Separate the model into different machines/accelerators (GPU/TPU)
- Breaking up a model to train efficiently on multiple device is still an active area of research and could be quite challenge.
- Achieved via pipeline parallelism
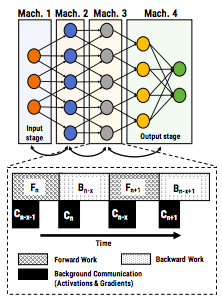
- GPipe – Google’s version of pipeline parallelism
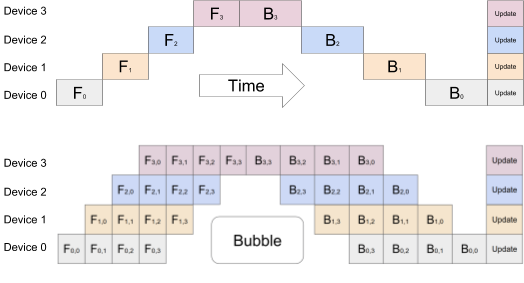
- Legend: F is forward pass and B is backward pass
- Top figure: When each layer of the model is split across different device naively, they still have to wait for each other because the forward and backward passes are sequential
- Bottom figure: When the mini-batch is further slip into micro-batches, each device can work on a portion of the micro-batch and does not need to wait for the entire mini-batch. For example, Device 0 is working on the second micro-batch while Device 1 is working on the first micro-batch in parallel. There is still some overhead because Device 1 still have to wait for Device 0 for the first micro-batch.
- In both figures: the update is only compute when the entire mini-batch (all micro-batches) are done with forward and backward propagations.
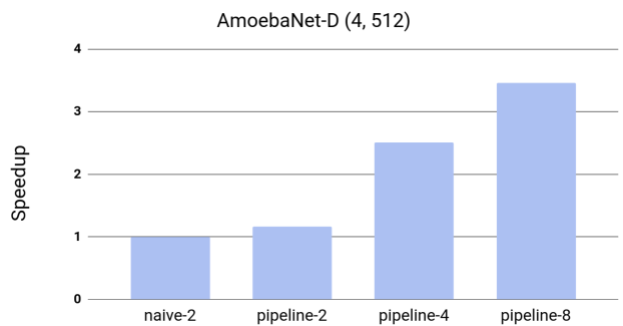
- When tested on AmoebaNet-D (4, 512) with 8 billion parameters, pipeline parallelism with GPipe is able achieve close to linear speedup
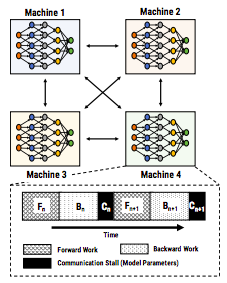
- Data parallelism (easier)
- Synchronized
- Separate the data into partitions
- Model is replicated into different workers (a machine or accelerator)
- Each worker perform forward and backward propagation to compute error and gradients for its responsible partition of the data in one epoch
- Each worker updates its model and send its update to all other workers so they are able to apply the same updates
- Keep model in sync in each epoch
- Workers need to be synchronized and wait for each others’ updates
- Communication
- All-reduce algorithm
- Every workers sends updates to every other workers
- Requires large bandwidth and information shared is replicated
- ring-reduce algorithm
- Workers form a ring and passes updates to next worker in the ring and every worker gets the information when the message passes one round in the ring
- Only send some part of the data each time so that every workers are using all the available bandwidth
- Reduce bandwidth because each worker can accumulate the gradients and sent the partial sum to the next worker so that after one round the total is obtained.
- All-reduce algorithm
- Asynchronized
- Parameter server
- TFJob (a component of Kubeflow) roles:
- Chief: orcheestrating training and perform checkpointing
- PS: parameter servers provide distributed data store
- Worker: actually doing the work, worker 0 might also be the chief
- Evaluation: compute eval metric during training
- Each worker has its own piece of data
- Each worker sends update to the parameter server asynchronously
- More efficient – no waiting time for the worker
- Different workers run at different pace
- Slower to converge (measured in the number of epoch) and lower accuracy
- TFJob (a component of Kubeflow) roles:
- Parameter server
- Synchronized
Application
- Uses Keras/Estimator APIs
- Tensorflow distribute.Strategy API
- One Device Strategy – no distribution, used for testing your distributed training code
- Mirrored Strategy – synchronous on multiple GPU on one machine
- Variables are mirrored across all replica of the model in all GPUs
- Conceptual variable called mirrored variable, which kept in sync using communication algorithm such as all-reduce
- Parameter Strategy
- Parameter server worker(s) – stores the parameters and maintains all updates
- Computation workers – feeding data into model
- Asynchronous by default, but can be done synchronously (although it would be less efficient)
- Multi-worker Mirrored Strategy
- Synchronous distributed training across multiple workers, each with potentially multiple GPUs
- Similar to MirroredStrategy, it creates copies of all variables in the model on each device across all workers
- Central Storage Strategy
- Synchronous but variables are not mirrored, instead they are placed on the CPU and operations are replicated across all local GPUs.
- TPU Strategy
- To take advance to TPU and TPU Pods, which are optimized for larger models and more cost effective than GPU
- Fault-tolerant
- Preserving training state (in a distribute file system) when a worker fails
- Keras backup and restore callback
- Don’t let the accelerator (GPU/TPU) idle
- Input pipeline needs to be efficient to keep the accelerator busy or else you might not get much benefit from the accelerator
- Memory constraint of large model
- The number of parameters is so large that a model cannot fit on a single machine (billions of parameters)
- Gradient accumulation
- Split mini-batches and only perform backprop after entire batch
- Memory swap
- Copy activation states back and forth among CPU and memory
One thought on “Training large models – distributed training”