Problem
When training a large model with multiple workers/accelerators, they might be idle when the data ingestion is not fast enough to catch up with the training.
- Accelerators are expensive
- Transformation run on CPU can be slow
- CPU/TPU/GPU can be waiting for data if model does not fit in memory
Solution
We should look into way to make sure the data ingestion is performant enough to keep the accelerator busy
- Input pipeline (tf.data)
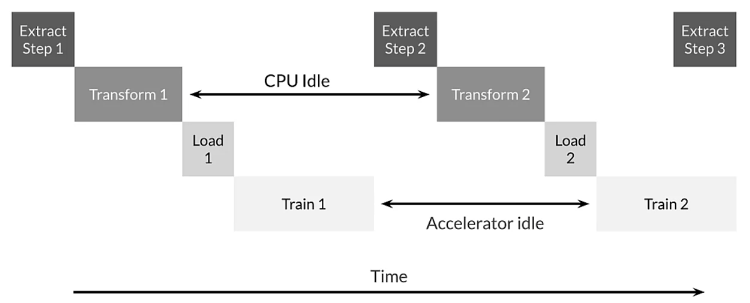
- Viewing pipeline as ETL
- Extract – reading data from hard drive or distributed file system
- Transform (map) – shuffle, augmentation, decompression, batching
- Load – load transformed data to accelerator (GPU/TPU)
- Input pipeline can take time, and we don’t want the accelerators to wait
- Idle CPU and Accelerator (don’t want this)
- Pipeline allows CPU to be running in parallel with GPU/TPU
- Viewing pipeline as ETL
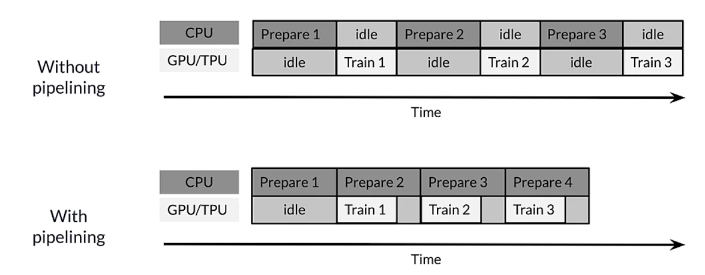
- Prefetching
- fetch data for the next training step while accelerator is training on the current step
- improve latency when the data is ready for training
- Parallel extraction and transformation
- open/read multiple data samples concurrently
- applying transformation on multiple CPU cores concurrently
- improve extraction/transformation throughput by reading multiple files
- interleaving the extraction and transformation
- Caching – read and transform data once into memory during first epoch, and cache the transformed input
- Reduce memory footprint – the order of the operation can affect how much memory is needed to buffer the records, we need to choose how much to produce and consume at each step
One thought on “Don’t let the accelerator (GPU/TPU) idle”