What is serving?
- Provide access to end users
- Provide service/app for interaction
- In ML workflow
- Batch inference
- Online Inference
- regularly retrained
- inference with the latest data available
- Metrics
- Latency – important for real time application
- Throughput – large amount of data
- Cost – compute and storage cost
Serving Strategies
Balances the model optimizing metric against the gating metric: accuracy, precision, recall vs latency, model size, CPU load
- Use accelerator
- NoSQL cache lookup
- Google cloud Memory Store
- sub-millisecond (managed version of redis memcache) read latency
- for 1000s of clients
- Google cloud Firestore
- millisecond latency
- slowly changing data
- Google cloud BigTable
- milliseconds read/write
- heavy read/write
- scale linearly
- AWS DynamoDB
- single digit read latency
- in-memory cache available
- Google cloud Memory Store
Deployment Options
- Huge data center
- On Prem
- Manually procure your own hardwares
- Profitable for large companies running ML jobs for long time
- Service Provider
- GCP, AWS, Azure
- More suitable for small companies
- 2 options:
- Create VMs and use prebuilt servers
- User provided managed ML workflow
- Optimizing resource utilization efficiency
- Can handle large model via REST API
- Can have higher accuracy with complex model (ex: disease detection)
- Latency could be a problem for some apps (ex: autonomous driving)
- Easy to rollback/update
- Platforms to set up service
- On Prem
- Embedded device
- Constraints
- GPU memory is low <4GB
- GPU is shared with other apps (there is only 1 GPU usually)
- Storage (users do not want to install large app)
- Power (users do not want to drain battery quickly or touch a hot phone)
- Very often try to optimize for latency if possible by going for edge device
- MobileNet – example of neural network architecture optimized for edge devices
- Constraints
Improving Latency
- Profile and benchmark the latency
- Per operator profiling
- Tweak number of threads for interpreter
- Can cause more variability in the performance since CPU is shared with other programs on the device
Options for Model Servers
Choose prebuilt servers: TF-serving, KF-serving, NVidia (Triton Inference Server), TorchServe
Tensorflow Serving integration
- Batch and real-time interface
- Multi-model serving
- For A/B Testing etc
- REST and gRPC endpoints
- Architecture
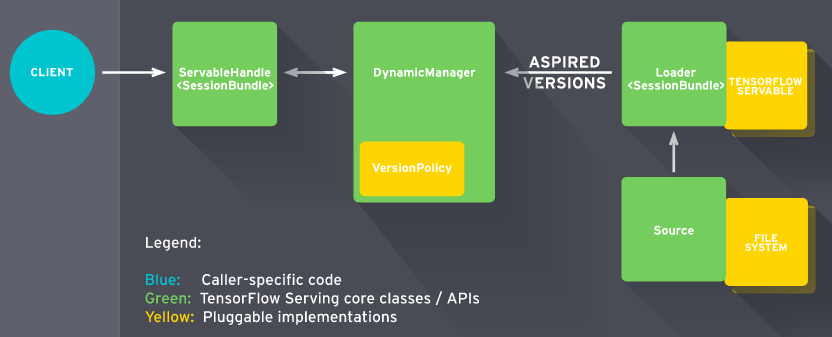
- TF-Servable
- Saved model
- Look up table
- Embedding
- Source
- Model weights
- Dynamic manager
- Load and unload servables
- Serving servable
Triton Inference Server (NVidia)
- Deploy AI models at scale
- From any framework: TensorFlow, NVIDIA® TensorRT™, PyTorch, MXNet, Python, ONNX, RAPIDS™ FIL (for XGBoost, scikit-learn, etc.), OpenVINO, custom C++, and more
- Model can be stored in any Cloud storage providers
- Use single GPU to deploy multiple models from different frameworks
- Multi-GPU to deploy one instances on each GPU for inference
- Support real-time, batch, and streaming inference
- Shared Cuda memory to improve performance
- Integrate with Kubernetes auto-scaling
TorchServe (AWS & Facebook)
- Batch and realtime inference
- Multi-model: A/B testing
- Monitor logs and metrics
Kubeflow Serving
- Serverless inferencing on Kubernetes