What is hyper-parameter tuning?
Since variables of the model that cannot be learned by the learning algorithm (via gradient descent) still need to be optimized to get the most high performance model, we have to search for the best values of these variable to use in the out loop. Examples in deep learning are the learning rate, the number of neurons in a layer, the number of layers, and even the architecture (connections) of the neural network.
There are many ways to do it such as grid search, random search, and Bayesian Optimization. This article goes over some of the popular tools for doing such hyper-parameter tuning/search.
Tools for hyper-parameter tuning
- Keras Autotuner
- Random Search
- Bayesian Optimization
- Hyperband
- Paper: Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization
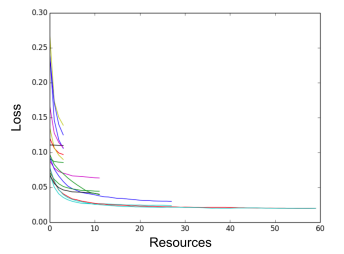
- Idea
- Randomly sample 64 hyper-parameter sets in the search space.
- Evaluate after 100 iterations the validation loss of all these.
- Discard the lowest performers of them to keep only a half.
- Run the good ones for 100 iterations more and evaluate.
- Discard a half.
- Run the good ones for 200 iterations more and evaluate.
- Repeat till you have only one model left.
- Sklearn
- TFT tuner
- Tensorflow Extended’s version of the tuner with similar API as Keras Tuner
- AutoML
- Contains Neural Architecture Search (NAS)
- Find best Neural Network for the data given
- Search Space
- Macro
- Stacking layers by chained structure space
- Multiple branches and skip connection by complex space
- Micro Architecture Search Space
- Operate at the cell level (instead of layers – a cell is a few layers connected together)
- Macro
- Search Strategy
- Grid search – exhaustive search
- Random search
- Bayesian optimization
- Assume prior distribution underlying that describe the performance over the architecture search space
- Use tested architectures to constrain the probability to calculate posterior to guide where to search next
- Evolutionary algorithm
- Randomly generate N architectures
- X best performance architectures selected for new generation (based on performance estimation strategy)
- The new offspring are copies of the parents with
- random alterations/mutations
- or combination of parents
- Y parents are removed/replaced by offsprings
- Too old
- Bad performance
- Reinforcement learning
- Agent tries to maximize reward
- Environment = search space
- Reward function = performance estimation strategy
- Example
- User Controller RNN to generate a sequences of strings that represent the layers
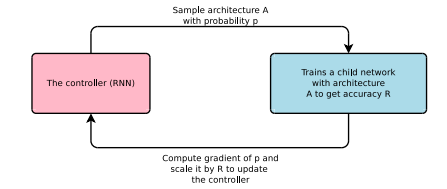
- See NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING
- Performance Estimation Strategy
- This is needed to guide the search
- Methods
- Directly measure validation accuracy
- Computationally heavy
- Slow/expensive -> impractical
- Lower fidelity estimate
- Train on subset of data
- Use lower resolution images
- Fewer filters and cells
- Con: tends to under-estimate the performance and relative ranking of the architecture performance might change, which makes this method unreliable
- Learning curve extrapolation
- Extrapolate the performance based on initial learning curve (small number of epochs) and terminate if the performance is not good
- Weight inheritance/network morphism
- Initialize the weights of new architectures based on previous architecture (similar to transfer learning)
- Network morphism
- New network inherits knowledge from parent network
- Directly measure validation accuracy
- Contains Neural Architecture Search (NAS)