Are you always confused about Type 1 and Type 2 errors?
The definition:

The mnemonic way
I can share some mnemonics that worked for me:
- Type One False Positive = Tiny Ox Flying Parrot
- Type Two False Negative = Thick Turtle Fight Night
Examples
But let’s understand it from an example.
Let’s give an example in a court case where we are trying to determine if a defendant is guilty.
We set up the null hypothesis where the defendant is not guilty, then we have the error types below:

Type I and Type II errors are basically cases when the courts ruling (prediction) is against the reality.
I have always understand it very well up to this point until I have to distinguish which one is which, but here is how we can think about it.
Question 1: can we flip the null hypothesis around? How do we choose which side?
Technically there is nothing that stops us from flipping the null hypothesis to “the defendant is guilty”, but in practice there are a few guiding principles.
- The null hypothesis should be the side that is the more conservative or the more likely case. In the court trial, we would typically assume the defendant is innocent until proven guilty.
- It takes more force/evidence to reject the null hypothesis. In the court trial, we expect to be presented with the data/evidence to prove someone guilty. The defendant should not be convicted with the lack of evidence.
- The term “positive” refers to proving the null hypothesis wrong.
Question 2: what is the cost of Type I vs Type II errors? which one is worse?
In the court trial, we generally consider convicting an innocent person is more costly than letting a criminal gets free. While not every would agree on this, this is part of the criminal ethics.
Alternatively, let’s talk about an example of cancer detection. How would you choose the null hypothesis?
- Option 1: Let the null hypothesis be “the patient has cancer”
- Option 2: Let the null hypothesis be “the patient does not have cancer”
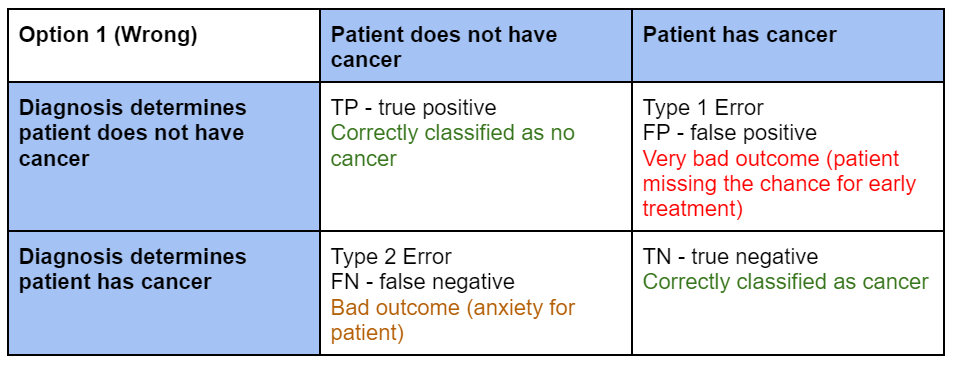
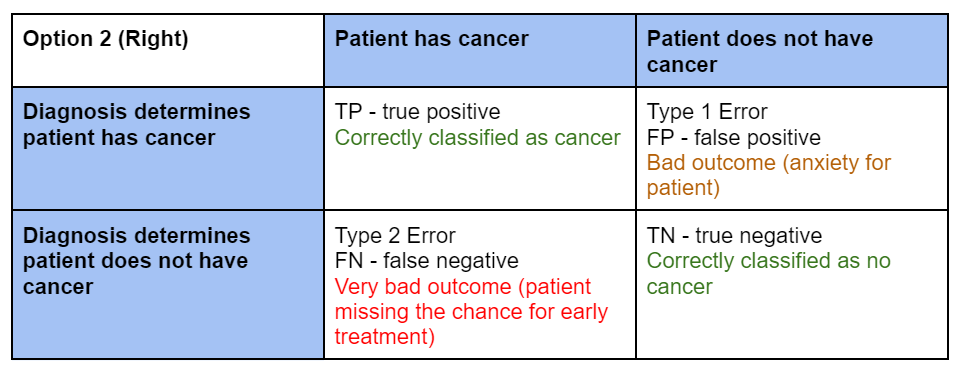
Compare the two options, we notice that using Option 1 as our null hypothesis, Type 1 Error is the more severe (costly) outcome. While in the Option2, Type 2 Error is the more severe outcome.
Applying the principle that null should represent the more conservative choice, we should choose Option 2
If you check the Option 2 against the court trial example above, you would notice
- Type 1 Error is more severe in the court trial example
- Type 2 Error is more severe in the cancer example
Conclusion: whether Type 1 or Type 2 is more important is case specific.
Question 3: how is the error type table relative to the 2×2 Confusion Matrix?
The confusion matrix in binary classification uses the convention below:
- Class 0 is the null hypothesis (e.g. the more common/conservative class)
- Class 1 is the class that we want to detect (e.g. the more rare class, which is the alternative hypothesis)

Question 4: can both Type 1 and Type 2 errors happen at the same time?
No, it’s not possible.
- You can only make Type 1 error when you predict class 1 (ie. reject null hypothesis)
- You can only make Type 2 error when you predict class 0 (ie. accept null hypothesis)
Since you cannot be both rejecting and accepting the null hypothesis at the same time, you cannot make both errors at once.
Takeaways
I hope you have learned something about the difference of Type 1 and Type 2 errors.
- Null hypothesis is the more common/conservative class
- Alternative hypothesis is the more rare class
- Type 1 Error (False Positive)
- predicting the rare case but it’s actually the common case
- reject the null hypothesis when you really should not
- Type 1 Error (False Positive)
- predicting the common case but it’s actually the rare case
- not reject the null hypothesis when you really should
One thought on “Difference of Type 1 and Type 2 Errors”