Git is one of the most popular Version Control System (VCS). You might have encountered Git command cheat sheets and tutorials on how to checkout a repository, commit, push and pull changes. It all seems to work fine until
- you start to collaborate with someone and you get merge conflict
- you make a mistake in committing something accidentally and don’t know how to revert
- you want to investigate a particular change sometime in the pass
- you want to pick and choose some diff to apply
- you don’t know whether you should rebase or merge
If you still have not mastered command by now, you might need to build up some fundamental concept in how Git works to truly see what the Git commands are doing.
Git workflow
To fully understand how Git works, we start with 4 “places” that git elements are stored in the git workflow perspective:
- Working directory
- The actual source files that you create and modify with your text editor
- Everything under your project directory excluding the hidden (.git) folder
- It reflect the current state (snap) of the project. As you checkout different branches/commits, the working directly will update to reflect that state.
- Git index/Staging directory/Staging area
- The preview area to get things “ready” to be committed to the local repository. You would add/remove changes to the staging area.
- You would declare your local changes from the working directory to be “staged” before committing to the local repository.
- The state of the Git index is found under the hidden (.git/index) folder.
- Local repository
- The locally committed state of the project that is intended to be pushed to the remote server.
- All the edit history with the actual object containing the all version of every file in the local and remove repository
- The hidden directory (.git) that contains all the objects excluding the (.git/index) folder.
- Remote repository
- The server that contains similar information as your local repository except it’s on a central server so that other users can also pull/push.
- The remote server is needed so that users don’t need to send the code changes to each other.
- It’s also known as Origin because it’s the original repository that you cloned from.
- It has its own (.git) folder on the server (just another remote computer).
Now it’s time to explain all the git command and how they interact with these 4 places in the git workflow:
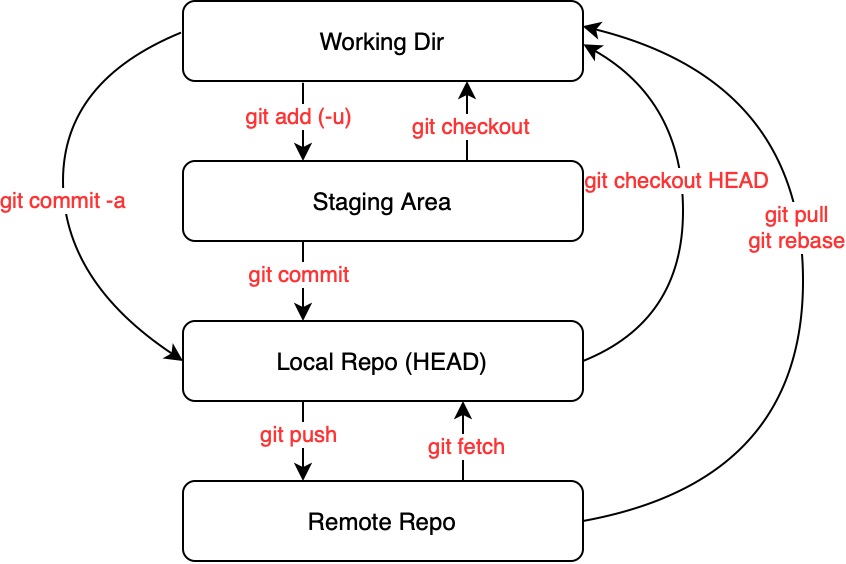
- git add (-u) <file_name>
- Adding the changes of a file or directory to the staging area.
- The “-u” argument means to only include updates on existing files that are tracked (See next section what the meaning of Tracked).
- To remove (exclude) a change from the staging area, you would run “git reset <file_name>”
- You can add multiple changes multiple times to the staging area before commit to the local repository.
- git commit
- It makes a snapshot (which is also called a commit) by packing all the changes in the staging area.
- This commit is added with a commit id (which is the commit hash) into the local repository.
- This adds a node (which is an event/action) in the commit “tree” representing the history (technically it’s a DAG, see later section on this underlying structure).
- You can commit multiple times to the local repository before pushing to remote repository.
- git commit -a
- Same as “git add” + “git commit”
- git push
- Copy the entire state of the local repository to the remove repository.
- git fetch
- Receiving the latest data from the the remote repository.
- If someone else has pushed to the remote repository, this information will reflect in the local repository.
- It does not change the working directory or the staging area, but it can expose the fact that your HEAD might be behind the remote repository
- git checkout HEAD
- Update the content of the working directory to the HEAD in local repository.
- Only works if there is no conflict.
- git merge
- Update the content of the working directory by combine the local change with the changes from remote.
- Create a merge commit that has 2 parent commits: the previous local and the remote
- git rebase
- Retain a more “linear” history by re-apply the local changes after the remote changes.
- Recreate a rebase commit that contains all the local changes
- git pull
- Same as “git fetch” + “git merge”
- git pull –rebase
- Same as “git fetch” + “git rebase”
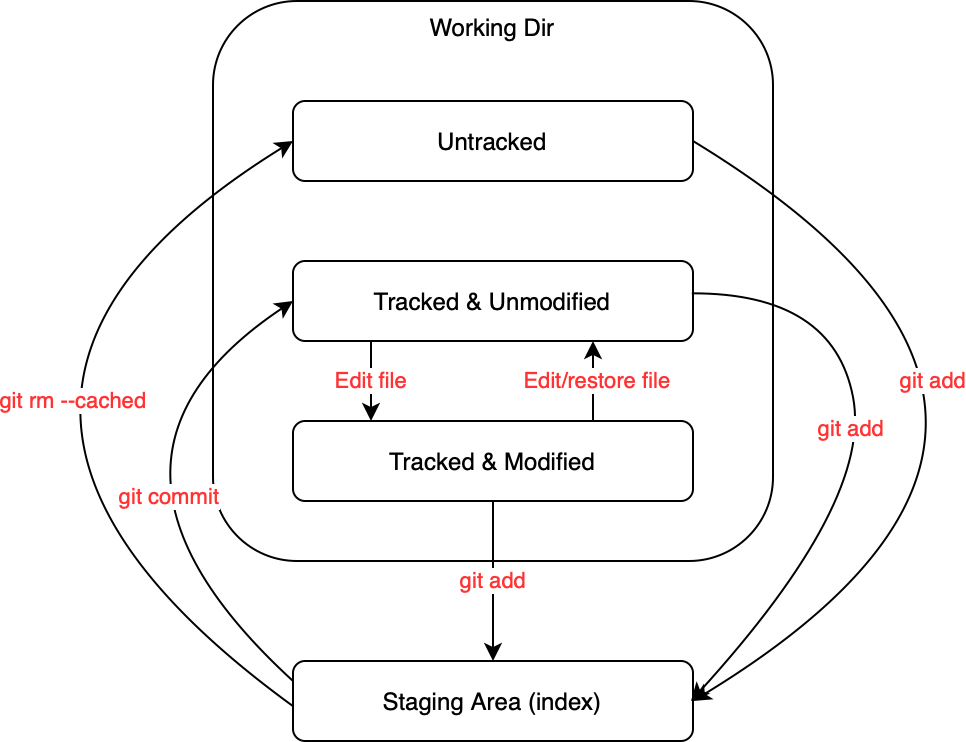
Tracked vs Untracked Files
Beside the workflow view above, each file/directory in the working directory can have 4 possible states:
- Untracked
- Git does not know about this file because it’s either new or ignored.
- New: by default news files are not tracked because you don’t want Git to start watching for newly generated log files or compiled binary output.
- Ignored: Git ignore certain files specified in the (.gitignore) file, which contains a list of rules on what to ignore for Git
- Running “git add” will put this file in the staging area.
- Git does not know about this file because it’s either new or ignored.
- Tracked and Unmodified
- Git is aware of this file because this file must have been added to Git via “git add” but currently there is no local changes on this file in the working directory.
- Running “git add” does not nothing because there is difference between the working directory and staging area.
- Tracked and Modified
- Git is aware of this file because this file must have been added to Git via “git add” and currently there is local changes on this file in the working directory.
- The change is not in the staging area yet so “git commit” will not include this change.
- Running “git add” would stage the change into the staging area.
- Staging Area
- All changes in the staging area are “ready” to be included when you run “git commit”
- As we already described in the earlier section, running “git commit” would generate a commit and send the changes to the local repository.
- Another effect is that the file in the working directory is back to “Tracked and Unmodified” state because there is no difference between the change in the staging area is gone (processed).
- Running “git rm –cached” essential asks Git to stop tracking a file (like undo “git add”)
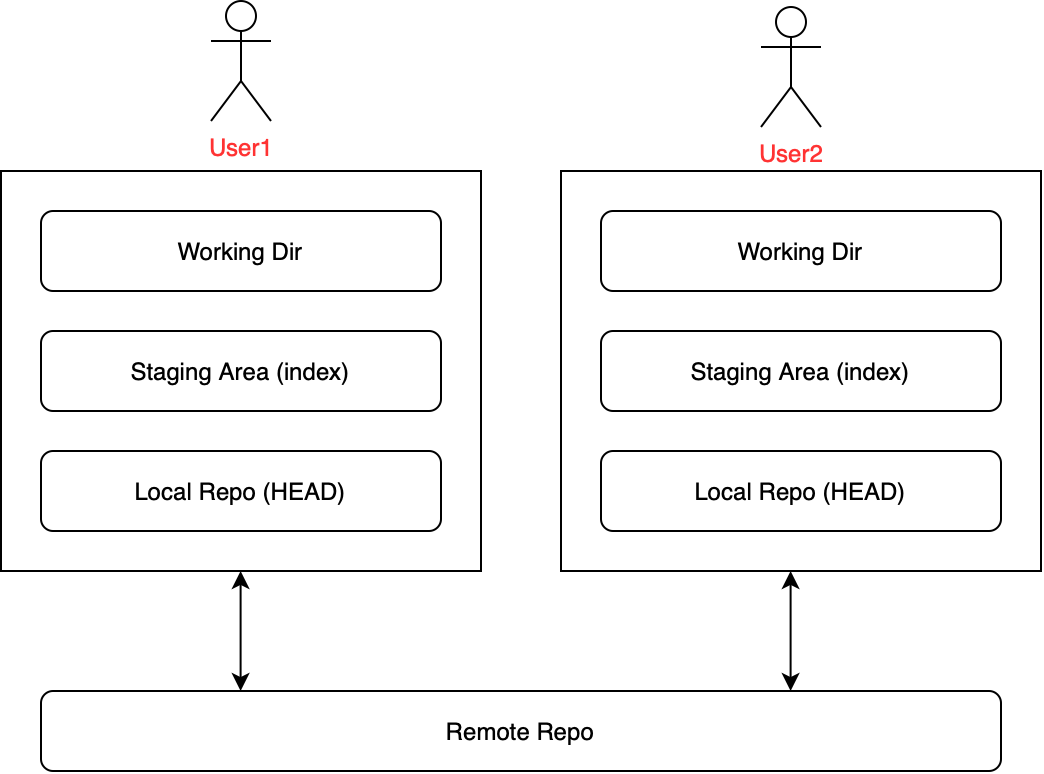
Git in collaboration
Git users basically collaborate on the same project by pulling/pushing changes from/to the remote repository.
- Every user has his/her private local repository.
- Users do not send/receive changes to either other, but only communicate to the Remote Repository.
- If User1 wants to show User2 something, User1 would push the change to the remote and User2 would need to pull the change from remote after User1.
Conflict when pulling/pushing
The above model works quite well when User1 and Users don’t modify the same place in the code at the same time. This can happen 2 ways:
- When running “git pull”
- “git pull” is same as “git fetch” + “git merge”
- Conflict happens during merging because you have committed a change in your local repository that touches the same place in the same file as another change from the remote (committed and pushed by someone else).
- The solution is to manually fix the merge conflict to create a merge commit locally that consolidate the commits on remote onto your local repository
- When running “git push”
- “git push” also implicitly does a “git fetch” and then tries to ask the remote to merge your commit into it
- Note that “git push” does not perform a merge on your local repository.
- As a result, the remote might have some other committed that modifies the same place as the commit that you are pushing.
- To resolve the conflict, you would need to do a “git pull” and remove the conflict in the merge, and then retry “git push” again.
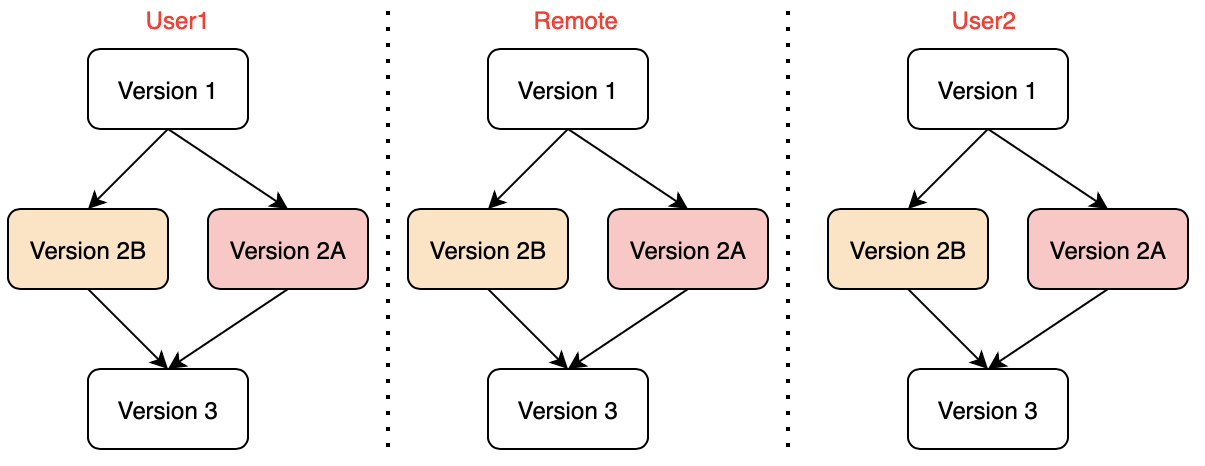
Let walk thru an example with a view on the commit graph:
- Initial state: we have User1 and User2 both in sync with Remote (ie. they both have pulled the latest from remote

- Both users make local changes:
- User1 makes a commit (Version 2A) in User1’s local repo but has not yet pushed to remote
- User2 makes a commit (Version 2B) in User2’s local repo but has not yet pushed to remote

- User1 pushes from local to remote successfully
- User2 is unaware of this change in remote
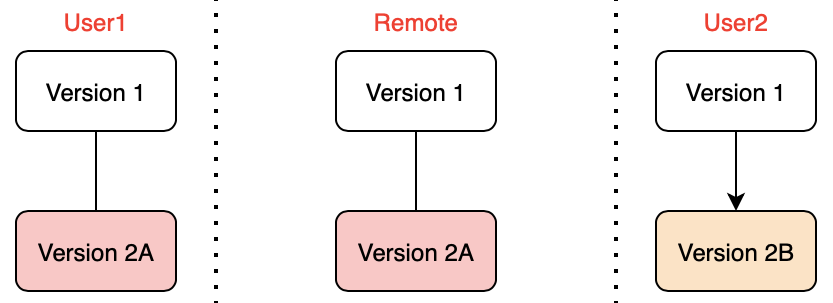
- User2 tries to “git pull” from remote (there are might or might not be a conflict)
- Regardless if there is a conflict, a merge commit Version 3 is created in User2’s local repository to combine Version 2A and 2B
- This merge commit is Version 3
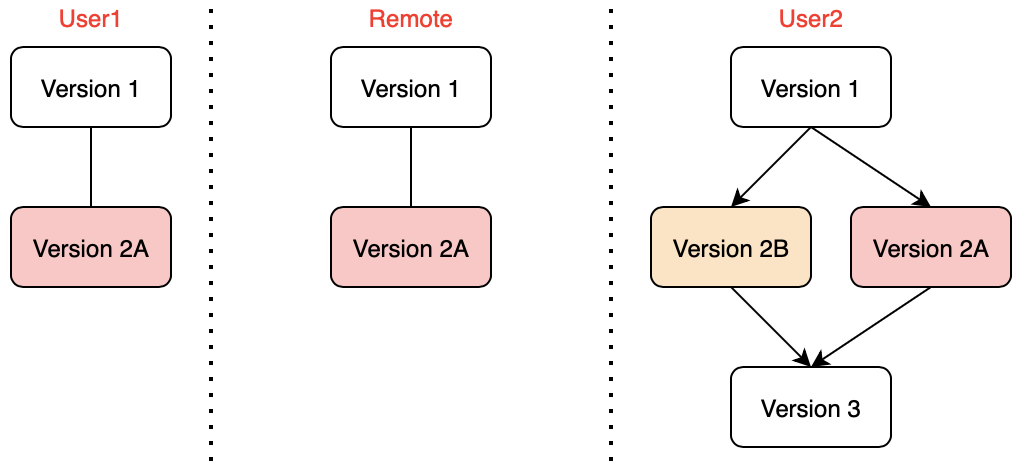
- User2 tries to “git push” the local repository to remote again
- This time, the push is successfully, and both Version 2B and merge commit Version 3 are copied to remote
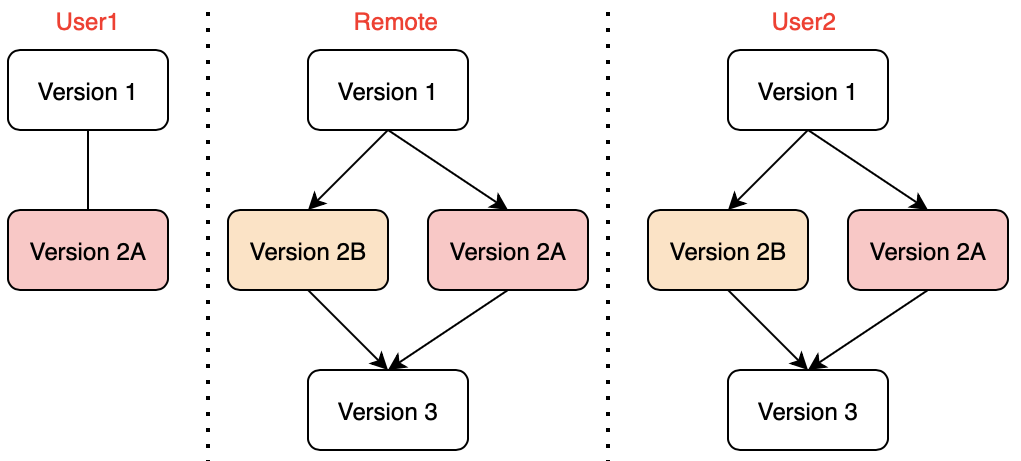
- User1 runs “git pull” and the changes on remote repository are copied back to User1’s local repository