Problem
In production ML, it’s not done after training and deploying the model.
- Blackbox
- Loss (ex: cross entropy and mse)
- Accuracy or error
- Ex: Tensorboard is a blackbox analysis tool
- White box – model introspection
- Knowing the internal model and examine part by part
- Ex:
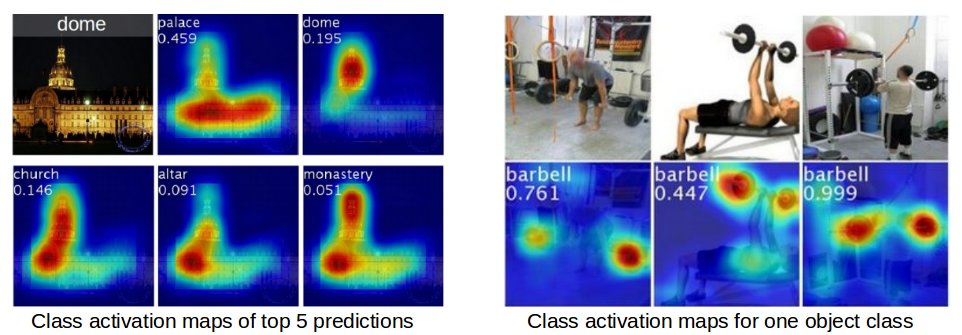
- Check CNN filter
- Localization: check activation of CCN to see which part of the image is impacting the decision
- Metric vs Objective
- Objective – use for gradient descent to optimize the parameters
- Metric – use for validation and/or post training evaluation (cannot be directly trained usually)
- Aggregate vs Slicing
- Aggregate model performance is the default when model is trained as the optimization should optimize for average performance
- Slicing needs to be done post training to see if certain sub populations have significantly degraded performance compared to the average population.
- TFMA (tensorflow-model-analysis)
- standalone pipeline or TFX pipeline component
- compares multiple versions of model
- uses ApacheBeam to run eval on all dataset after training
- slicing over one or more feature dimension using tfma.EvalConfig
Robustness
Often it’s not enough to just make sure your model can generalize to the typical case, but also it should be robust against changes or errors in some part of the features. Of course, no model can be robust to everything, but the goal is not to have a model that just degrades significantly at some slight change of the data. Below are some techniques to measure the robustness of your model.
- Benchmark
- Simple model that solves the same problem (ie. linear/logistic regression)
- Easy to interpret
- Hard to get wrong and easy to test and ensure correctness
- Compare the complex model to this benchmark model as a baseline
- Further slice the data to compare if any specific sub-population is performing worse than the benchmark model
- Sensitivity analysis
- Simulate changes in the data and observe how the model prediction changes
- Tensorflow What-If-Tool
- Partial dependence plot (PDP)
- Visualize the effect of one or more input feature to the model output
- Adversarial attack
- Random attack
- High volume of random input data to the model
- Exploits math and software bugs
- A way to get started in testing the model
- Image example: Fast Gradient Sign Method Attack
- White box attack
- Find the gradient that maximizes the loss with little distortion to the original input
- Update the input in a way that in the bad directly, but not the same as gradient ascent because it uses the sign of the gradient only to make a perturbation to the original input
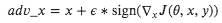
- where
- adv_x : Adversarial image.
- x : Original input image.
- y : Original input label.
- 𝜖 : Multiplier to ensure the perturbations are small.
- 𝜃 : Model parameters.
- 𝐽 : Loss.
- Harms
- Information – to extract information from model
- Model inversion – recreate training data
- Membership inference – was this person’s data used for training
- Model extract – recreate the model
- Behavior – to alter the behavior of the model
- Poisoning: Insert malicious data into training data
- Evasion: Intentionally cause the model to misclassify
- Information – to extract information from model
- Harden the model against adversarial attack
- Add adversarial example to training
- Framework:
- cleverhans – python library
- foolbox
- However, it limits your ability to test your model because you are almost testing your training data
- Defensive Distillation
- Same teacher and student network structure – use a network’s own structure to improve resilience against attacks
- Increase model robust
- Decrease sensitivity
- Random attack
- Residual analysis
- Measures the difference between prediction and ground truth (more applicable to regression than classification)
- You want randomly distributed errors, but if there is correlation of the error with any (unused) features, it means something can be improved in the model. It means you might have left out an important feature.
- Check for auto-correlation if there is sequential nature in the data (time series)

One thought on “Production ML: Model Analysis”